Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
Published:
We found that people forecasted COVID-19 more accurately using tables than graphs of historical data. 
Recommended citation: Fansher, M., Adkins, T.J., Lalwani, P., Quirk, M., Boduroglu, A., Lewis, R. L., Shah, P., Jonides, J.(2020). "How well do ordinary Americans forecast the growth of COVID-19? ." PsyArXiv. https://psyarxiv.com/2d5r9/
Published:
We find that people prepare goal-directed actions more quickly when they are motivated by reward. 
Recommended citation: Adkins, T.J. and Lee, T.G. (2021). "Reward accelerates the preparation of goal-directed actions." PsyArXiv. https://doi.org/10.31234/osf.io/hv9mz
Published:
We find that people allocate more memory resources to goal-relevant representations when they are motivated to obtain reward. 
Recommended citation: Brissenden, J.A., Adkins, T.J., Hsu, Y.T., and Lee, T.G. (2021). "Reward influences the allocation but not the availability of resources in visual working memory." bioRxiv. https://www.biorxiv.org/content/10.1101/2021.06.08.447414v1
Published:
We found that people were less hesitant about the J&J vaccine if they viewed an icon array representing the risk of side-effects![]()
Recommended citation: Fansher, M., Adkins, T.J., Lalwani, P., Boduroglu, A., Quirk, M., Carlson, M., Lewis, R. L., Shah, P., Zhang, H., Jonides, J.(2021). "Icon Arrays Reduce Concern Over COVID-19 Vaccine Side Effects: A Randomized Control Study." PsyArXiv. https://psyarxiv.com/dcx8p/
Published in IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2021
Cloud-based enterprise search services (e.g., AWS Kendra) have been entrancing big data owners by offering convenient and real-time search solutions to them. However, the problem is that individuals and organizations possessing confidential big data are hesitant to embrace such services due to valid data privacy concerns. In addition, to offer an intelligent search, these services access the user’s search history that further jeopardizes his/her privacy. To overcome the privacy problem, the main idea of this research is to separate the intelligence aspect of the search from its pattern matching aspect. According to this idea, the search intelligence is provided by an on-premises edge tier and the shared cloud tier only serves as an exhaustive pattern matching search utility. We propose Smartness at Edge (SAED mechanism that offers intelligence in the form of semantic and personalized search at the edge tier while maintaining privacy of the search on the cloud tier. At the edge tier, SAED uses a knowledge-based lexical database to expand the query and cover its semantics. SAED personalizes the search via an RNN model that can learn the user’s interest. A word embedding model is used to retrieve documents based on their semantic relevance to the search query. SAED is generic and can be plugged into existing enterprise search systems and enable them to offer intelligent and privacy-preserving search without enforcing any change on them. Evaluation results on two enterprise search systems under real settings and verified by human users demonstrate that SAED can improve the relevancy of the retrieved results by on average ≈24% for plain-text and ≈75% for encrypted generic datasets.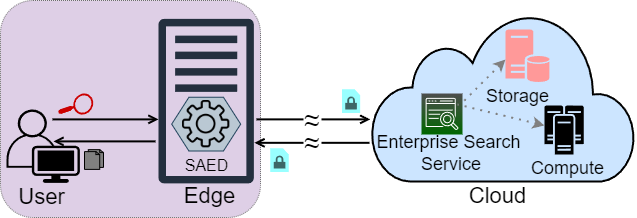
Recommended citation: Sm Zobaed, Mohsen Amini Salehi, and Rajkumar Buyya (2021). "SAED: Edge-Based Intelligence for Privacy-Preserving Enterprise Search on the Cloud." International Symposium on Cluster, Cloud and Internet Computing (CCGrid). 21013933. https://ieeexplore.ieee.org/abstract/document/9499649
Published in Journal of Concurrency and Computation: Practice and Experience, 2021
Cloud-based enterprise search services (e.g., Amazon Kendra) are enchanting to big data owners by providing them with convenient search solutions over their enterprise big datasets. However, individuals and businesses dealing with confidential big data (e.g., criminal reports) are reluctant to fully embrace such cloud services due to valid data privacy concerns. Solutions based on client-side encryption have been developed to mitigate these concerns. Nonetheless, such solutions hinder data processing, especially, data clustering, which is pivotal in applications such as real-time search on large corpora (e.g., big datasets). To cluster encrypted big data, we propose privacy-preserving clustering schemes, called ClusPr, for three forms of unstructured datasets, namely static, semi-dynamic, and dynamic. ClusPr functions based on statistical characteristics of the datasets to: (A) determine the suitable number of clusters; (B) populate the clusters with topically relevant tokens; and (C) adapt the cluster set based on the dynamism of the underlying dataset. Experimental results, obtained from evaluating ClusPr against other schemes in the literature, on three different test datasets demonstrate between 30% to 60% improvement on the cluster coherency. Moreover, we notice that employing ClusPr within a privacy-preserving enterprise search system can reduce the search time by up to 78%, while improving the search accuracy by up to 35%.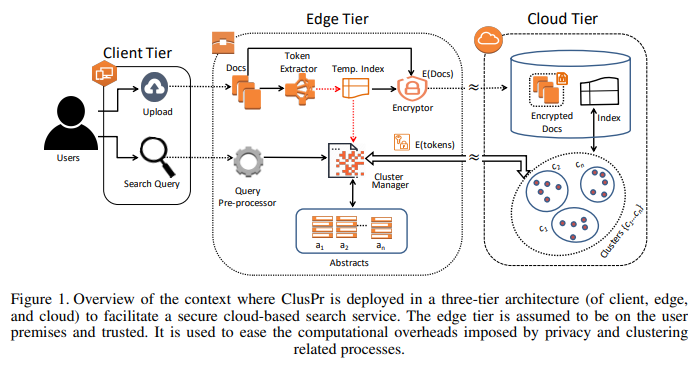
Recommended citation: SM Zobaed, Mohsen Amini Salehi (2022). "Privacy-Preserving Clustering of Unstructured Big Data for Cloud-Based Enterprise Search Solutions." Concurrency and Computation: Practice and Experience. https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.7160
Published in Proceedings of Utility Cloud Computing Conference, 2022, 2022
Smart IoT-based systems often desire continuous execution of multiple latency-sensitive Deep Learning (DL) applications. The edge servers serve as the cornerstone of such IoTbased systems, however, their resource limitations hamper the continuous execution of multiple (multi-tenant) DL applications. The challenge is that, DL applications function based on bulky “neural network (NN) models” that cannot be simultaneously maintained in the limited memory space of the edge. Accordingly, the main contribution of this research is to overcome the memory contention challenge, thereby, meeting the latency constraints of the DL applications without compromising their inference accuracy. We propose an efficient NN model management framework, called Edge-MultiAI, that ushers the NN models of the DL applications into the edge memory such that the degree of multi-tenancy and the number of warm-starts are maximized. Edge-MultiAI leverages NN model compression techniques, such as model quantization, and dynamically loads NN models for DL applications to stimulate multi-tenancy on the edge server. We also devise a model management heuristic for Edge-MultiAI, called iWS-BFE, that functions based on the Bayesian theory to predict the inference requests for multi-tenant applications, and uses it to choose the appropriate NN models for loading, hence, increasing the number of warm-start inferences. We evaluate the efficacy and robustness of Edge-MultiAI under various configurations. The results reveal that Edge-MultiAI can stimulate the degree of multi-tenancy on the edge by at least 2× and increase the number of warm-starts by ≈ 60% without any major loss on the inference accuracy of the applications.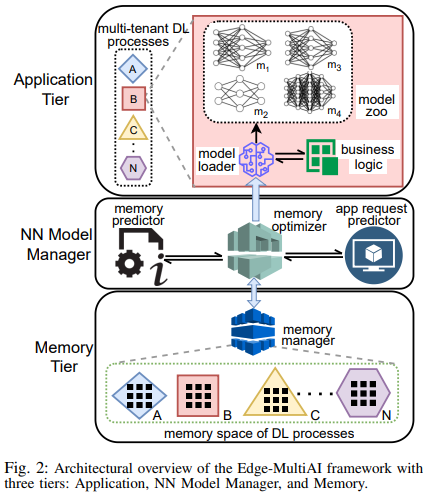
Recommended citation: SM Zobaed, Ali Mokhtari, Jaya Prakash Champati, Mathieu Kourouma, Mohsen Amini Salehi (2022). "Edge-MultiAI: Multi-Tenancy of Latency-Sensitive Deep Learning Applications on Edge." Utility Cloud Computing Conference. https://arxiv.org/abs/2211.07130
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University of Louisiana at Lafayette; Computing and Informatics Department, 2023
Information Technology Infrastructure
Undergraduate course, University of Louisiana at Lafayette; Computing and Informatics Department, 2023
Information Assurance and Security